- reCAPTCHA is One of the Popular Problems with Scraping and Retrieving Data
- Method 1: Make Use of Rotating Proxies.
- Method 2: Use IP Addresses from the Google Cloud Platform
- Method 3: Scrape the Web Slowly
- Method 4: Web Scraping at Various Times of the Day
- Method 5: Make use of a CAPTCHA-resolving service
- Method 6: Scrape the Google cache
Since Google introduced the Internet bot protection system CAPTCHA, based on zero-trust security, many procedures have become difficult to access, including scraping sites. The role of AI didn’t just end at creating dynamic and responsive websites, but also scrapping data off it. To be able to automatically process information, special programs began to be used but it affected users on the block. Of course, the operation can be done manually or automatically with the help of a bot or web scrapper.
There is a common misperception that website scraping is unlawful. However, this is not the case unless you are attempting to access non-public material (publicly inaccessible data like login credentials). But this information is always protected in most of the sites.

One of the most common methods of protection is a captcha. Or a banal block of IP addresses that you may encounter while doing scraping. In this article, we will discuss how to avoid captcha without becoming blocked and some of the best strategies for extracting data from the web.
reCAPTCHA is One of the Popular Problems with Scraping and Retrieving Data
The CAPTCHA API has become an obstacle to automating many processes. Scraping and collecting publicly available data is not prohibited. This is a perfectly legal procedure that is not prosecuted.
Originally, CAPTCHA was introduced to prevent cyber-attacks, obtaining users’ personal data without their consent, stealing content, and other adverse actions. But the level of protection turned out to be high enough to protect not only from intruders but also from any other actions with content.
This has caused many difficulties not only for attackers but also for business owners, marketers, analysts, SEO optimizers, and other professionals. Scraping actions quickly attract the attention of security algorithms. Within a few minutes of scraping, and collecting information, the IP address is blocked.
And of course, people immediately began to look for a solution to this problem. To avoid this, some choose to buy a proxy server from a trusted provider, like PrivateProxy. This option has a number of advantages:
- This is a legal technology that is highly trusted by search engines and other anti-spam and anti-scraping systems.
- The proxy server is dynamic. It changes at user-specified intervals.
- The possibility of getting a ban is reduced to zero.
- Network access is anonymous and secure.
- The speed of information exchange is high.
Using a proxy and some other software, you can scrape data from sites without being blacklisted by the site. Next, we will look at several methods that will help you successfully scrape data.
Also Read: Received a Google Verification Code Without Requesting? Is it a…
Method 1: Make Use of Rotating Proxies.
Your proxy is your natural footprint on the internet. If you do not commit any extraordinary actions, then everything is in order. But if you are trying to scrape data, there are high chances of you getting blocked.
By inspecting the server log files, website owners can recognize your footprint and prevent your web scrapers if you submit repeating requests from the same IP address. You may circumvent this by using rotating proxies.
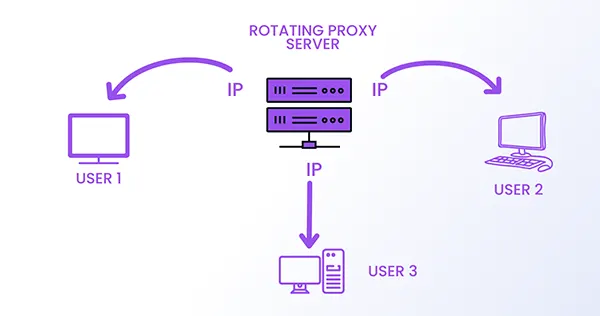
A rotating proxy server assigns a fresh IP address from a pool of proxies. To evade detection by website owners, you must utilize proxies by trusted providers, like Smartproxy, and cycle our IP addresses. All you need to do is buy the service package that suits you. But in no case, use free proxy servers.
Free proxies tend to vanish rapidly. Furthermore, free proxies are overused on the Internet and are already blacklisted by the majority of anti-scratching applications. You may even automate the procedure by using free proxies to avoid disrupting the scratching process.
Method 2: Use IP Addresses from the Google Cloud Platform
Using Google Cloud Functions as the hosting platform for your web scraper in conjunction with changing the user agent to Google Bot might be beneficial. The website will indicate that you are a Google Bot rather than a scraper.

Google Bot is a Google web crawler that scans sites every few seconds and gathers site pages to generate a search index for the Google search engine. Because most websites do not prohibit Google Bot, using Google Cloud computing combined with AI as a hosting platform increases the likelihood that your crawler will not be blacklisted.
Method 3: Scrape the Web Slowly
One thing you need to know while web scrapping is to take breaks. When you scrape data with an automated scraper, the web scraper scratches the data at an unnatural rate that anti-scraper plugins quickly identify. By adding delays and unpredictable actions to our scraper, you can make it appear human and avoid detection by website owners.

Sending too many queries at once might cause the website to fail for all visitors. Keep the number of queries below a certain threshold to avoid overloading the website’s server and having your IP blocked.
Furthermore, you may examine the time between two queries by utilizing a site’s robot file.txt. On the crawler page.txt, there is frequently a crawl delay field that specifies the duration between queries to prevent being identified as a crawler.
Method 4: Web Scraping at Various Times of the Day
Connecting to the same website at different times of the day minimizes your carbon footprint as well. For example, if you normally scratch at 8:00 a.m. daily, the security algorithm might analyze your pattern and detect you as a bot.
Start scratching at 8:20 a.m. or 8:25 a.m. for the following several days. Adding a few minutes to your daily start time might assist you in avoiding the crawler’s detecting algorithm.
Method 5: Make use of a CAPTCHA-resolving service
CAPTCHA is used by most websites to identify bot traffic. You may simply get around this extra degree of protection by using a CAPTCHA resolving service such as 2captcha. The implication is that CAPTCHA solution services are more expensive and can lengthen the time required to retrieve data from websites. Consider the additional time and cost you may pay if you employ a CAPTCHA-solving service.
Method 6: Scrape the Google cache
You may use Google’s cache to retrieve data from websites whose content updates seldom. Certain webpages are cached by Google, so rather than requesting the original, you can obtain its cached data. To access the cache on any web page, precede the URL with the website’s URL.
Given the various methods we have discussed here, you’ll definitely find the best ones that work well for you. Among them, the use of proxy servers is known to be the best, most flexible method for web scraping. While using Google Cloud Computing to prove yourself as an authentic host seems to be a strategy, you should also ensure taking precautions while scrapping web for data. Make sure to take a short break before scrapping another website on your list.